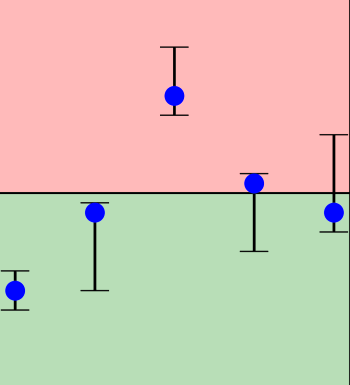
To address safety concerns in industrial systems, we propose a framework for forecasting CPU load with respect to a predetermined threshold, allowing customers to add tasks from a predefined library. Existing tools, akin to Windows Task Manager, provide limited insights due to their aggregate nature and high computational overhead. Our approach uses conformal prediction for rapid uncertainty-aware forecasts and Shapley value analysis to quantify individual task contributions to the CPU load. This proof-of-concept framework improves system safety assessment by addressing key research questions in load prediction and validation, paving the way for refined measurement methodologies in industrial applications.
@inproceedings{Jelacic2025-wm,title={A conformal prediction-based framework for {CPU} load
forecasting: A black-box approach},author={Jelačić, Edin and Seceleanu, Cristina and Backeman, Peter and Xiong, Ning and Seceleanu, Tiberiu and Jantsch, Axel},booktitle={2025 IEEE 49th Annual Computers, Software, and Applications
Conference (COMPSAC)},publisher={IEEE CS},year={2025},eventtitle={2025 IEEE 49th Annual Computers, Software, and Applications
Conference (COMPSAC)},venue={Toronto, ON, Canada},pages={361--370},date={2025-07-08},urldate={2025-08-28},keywords={conformal prediction; Shapley; CPU; forecasting; load},language={en},}
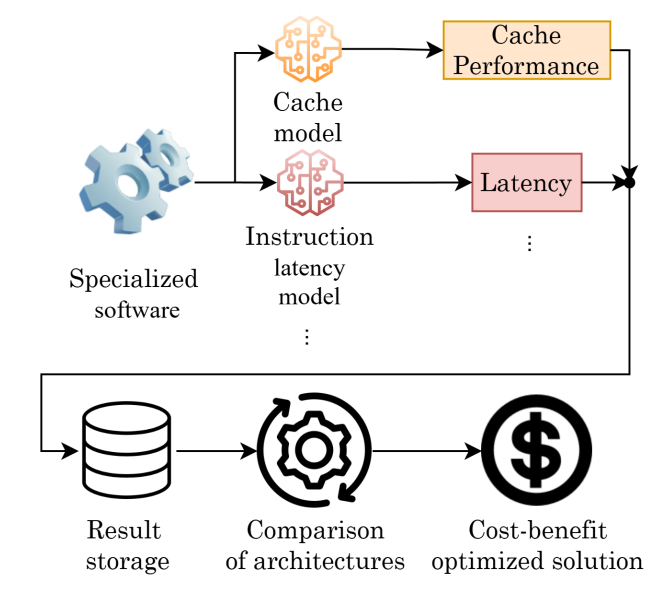
Integrating machine learning into computer architecture simulation offers a new approach to performance analysis, moving away from traditional algorithmic methods. While existing simulators accurately replicate hardware, they often suffer from slow execution, complex documentation, and require deep CPU knowledge, limiting their usability for quick insights. This paper presents a deep learning-based approach for simulating a key CPU component, cache memory. Our model "learns" cache characteristics by observing cache miss distributions, without needing detailed manual modeling. This method accelerates simulations and adapts to different program needs, demonstrating accuracy comparable to traditional simulators. Tested on Sysbench and image processing algorithms, it shows promise for faster, scalable, and hardware-independent simulations.
@article{Jelacic2025-rb,title={Machine learning-based cache miss prediction},author={Jelačić, Edin and Seceleanu, Cristina and Xiong, Ning and Backeman, Peter and Yaghoobi, Sharifeh and Seceleanu, Tiberiu},journaltitle={Int. J. Softw. Tools Technol. Transf.},publisher={Springer},year={2025},volume={27},issue={1},pages={53--80},date={2025-02-22},urldate={2025-04-23},language={en}}
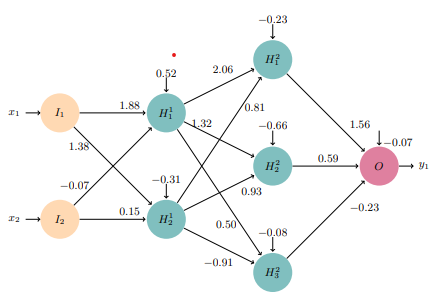
Machine learning is an increasingly popular method for modeling complex systems, to make predictions or recognize data patterns. A common machine learning model is the neural network, which can be trained to represent complicated functions to a high accuracy. While neural networks often grow large and complex, recent work is looking in how to abstract networks to yield simpler representations, while retaining some property of the original network. For instance, for every input, the abstracted network’s output should be at least as large as the original. In this work, we build on previous ideas and extend them to allow for removing inputs, obtaining an under/over-approximating network instead. Further, we show how to combine these approximating networks to identify inputs which have a low impact on the final output.
@inproceedings{Backeman2023,title={Abstraction-based reduction of input size for neural networks},author={Backeman, Peter and Jelačić, Edin and Seceleanu, Cristina and Xiong, Ning and Seceleanu, Tiberiu},booktitle={Automated Reasoning and Verification - 3rd Workshop on Tools and Benchmarks, ISoLA 2023},publisher={Springer},year={2023},keywords={Neural network;Abstraction;Dimensionality reduction;Feature Selection},}
 HASCo: A Hybrid AI Simulation Compiler for Semantic Accident ReconstructionIn , 2026In preparation
HASCo: A Hybrid AI Simulation Compiler for Semantic Accident ReconstructionIn , 2026In preparation